

Humanoid robots hold enormous promise for performing everyday human tasks—from household chores to industrial assembly. Yet a central challenge remains unresolved: how can robots reliably manipulate diverse objects in unseen environments without requiring massive training datasets?
A recent paper from Wuhan University introduces RGMP (Recurrent Geometric-prior Multimodal Policy), a novel framework designed to tackle this exact problem. The work addresses a key limitation of current data-driven robot manipulation systems: while they perform well in training conditions, they often fail to generalize beyond them.
Why Geometry Matters in Robot Manipulation
Most modern manipulation policies rely heavily on large-scale imitation learning or diffusion-based models. These approaches are data-hungry and tend to overlook geometric reasoning, such as object shape, spatial relationships, and affordances—information that humans intuitively use when choosing how to grasp or move objects.
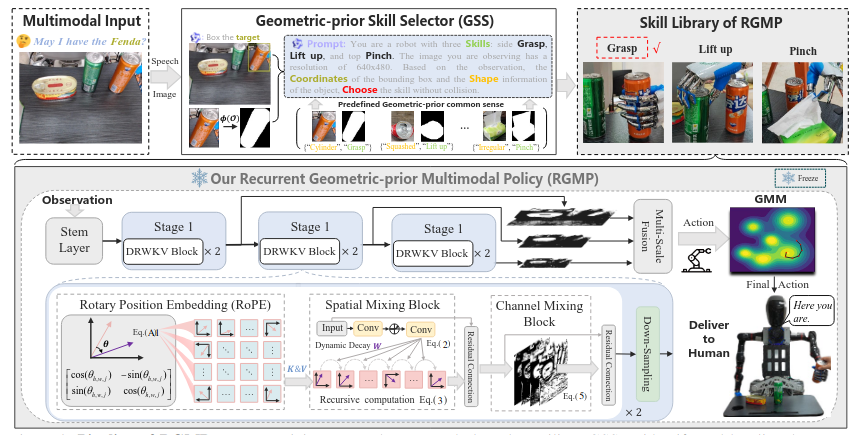
RGMP introduces geometry as a first-class concept. At its core is the Geometric-prior Skill Selector (GSS), which integrates vision-language models with simple but powerful geometric priors. By reasoning about object shape (e.g., cylindrical vs. squashed) and position, the robot can select an appropriate manipulation skill—such as grasping, lifting, or pinching—even in unfamiliar scenes.
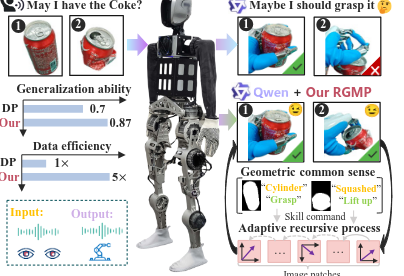
Data-Efficient Motion Through Recursive Spatial Reasoning
Skill selection alone is not enough; robots must also execute precise motions with limited demonstrations. To achieve this, the authors propose the Adaptive Recursive Gaussian Network (ARGN). Instead of learning raw trajectories from scratch, ARGN recursively models spatial relationships between the robot and its environment, building a compact spatial memory of task-relevant regions.
Motion generation is further refined using Gaussian Mixture Models, enabling the robot to represent multiple plausible action modes rather than collapsing to an average movement. This design dramatically improves robustness when training data is scarce.
Strong Results with Minimal Demonstrations
In real-world experiments on both a humanoid robot and a dual-arm platform, RGMP achieved 87% success in generalization tests, outperforming state-of-the-art methods such as Diffusion Policy. Remarkably, it required five times fewer training demonstrations to reach comparable or better performance.
These results suggest that combining geometric-semantic reasoning with data-efficient visuomotor learning may be a key step toward scalable, real-world humanoid robots.
Looking Ahead
The authors envision extending RGMP toward functional generalization—where learning how to manipulate one object allows a robot to infer how to handle many others with similar affordances. Such capabilities could significantly reduce the need for manual teaching and accelerate deployment in homes, factories, and service environments.
For researchers and students working on humanoid robotics, RGMP offers a compelling blueprint: intelligence in manipulation may come not from more data alone, but from better structure, geometry, and reasoning.


